NoSQL
Qu’est-ce que NoSQL?
NoSQL signifie “Not Only SQL” (“pas seulement SQL”) et désigne un ensemble de systèmes de gestion de base de données. Cette catégorie de SGBD abandonne de nombreuses fonctionnalités classiques des SGBD-relationnel au profit de la simplicité, de la performance et d’une scalabilité élevée.
Pourquoi est apparu NoSQL?
Ces dernières années, les grands acteurs du web tels que Google, Facebook ou Amazon, ont eu à traiter des volumes de données de plus en plus gros. Les performances fournies dans cette situation par les bases de données relationnelles étant jugées trop faibles, ils ont décidé de créer leur propre SGBD.
Contrairement au SQL, le NoSQL doit être capable de gérer l’extensibilité de la base, la présence d’enregistrements de taille différente, et l’indexation de grandes quantités de documents. Certains modèles de NoSQL ont aussi été prévus pour gérer des réécritures fréquentes, alors que le les bases de données relationnelles sont surtout optimisées pour la lecture. Il n’existe pas un seul modèle de NoSQL mais plusieurs.
Le principe de fonctionnement
Les bases de données NoSQL s’inspirent du théorème CAP d’Eric Brewer:
- Consistency (consistance)
- Availability (haute disponibilité)
- Partition-tolerance (tolérant au partitionnement)
Seul deux des trois principes peuvent être respectés en même temps, dans la plupart des cas ce sont les deux derniers qui sont mis en oeuvre. En effet, les géants du web préfèrent avoir un site rapide avec une erreur sur les stocks (non mise en oeuvre du principe de consistance) qu’avoir un site web très lent et des stocks exactes à un instant t (mise en oeuvre du principe de consistance à la place de la haute disponibilité). Quand on sait qu’un dixième de seconde de latence fait perdre 1% de ventes à Amazon, cela semble justifier ce choix.
Il existe quatre type de base de données NoSQL:
- Orienté clé -valeur
- Orienté colonne
- Orienté document
- Orienté graphe
Les différents types de bases de données NoSQL
Orienté clé-valeur
Cette représentation est la plus simple, elle associe une clé à une valeur comme le montre le schéma ci-après.
![]()
Elle est très adaptée aux caches ou aux accès rapides aux informations dans la mesure où les lectures et écritures sont réduites à un accès disque simple. On en trouve trois implémentations principales : Riak, Redis et Voldemort.
Orienté colonne (découle de clé-> valeur)
Cette représentation est la plus proche des tables des bases de données relationnelles. Comme le montre le schéma ci-dessus, une clé peut avoir plusieurs valeurs ce qui est équivalent au fait qu’une ligne peut avoir plusieurs colonnes en base de données relationnelles. On en trouve deux implémentations: Hbase et Cassandra (voir la partie sur les solutions du marché).

Orienté document (découle de clé-> valeur)
Cette représentation découle de la représentation clé-valeur, sauf que la valeur peut à nouveau être représentée par un document comme le montre le schéma ci-après:

Cette représentation est considérée comme la plus adaptée au monde d’internet. Les données sont hiérarchisées, à l’image de JSON ou XML. On en trouve deux implémentations: MongoDB (utilisé par SourceForge) et couchDB.
Orienté graphe
Les bases de données orientées graphe sont très différentes des bases de données relationnelles. Au lieu de fonctionner avec des tables, ce modèle s’appuie s’appuie sur deux niveaux de données : les noeuds et les relations.
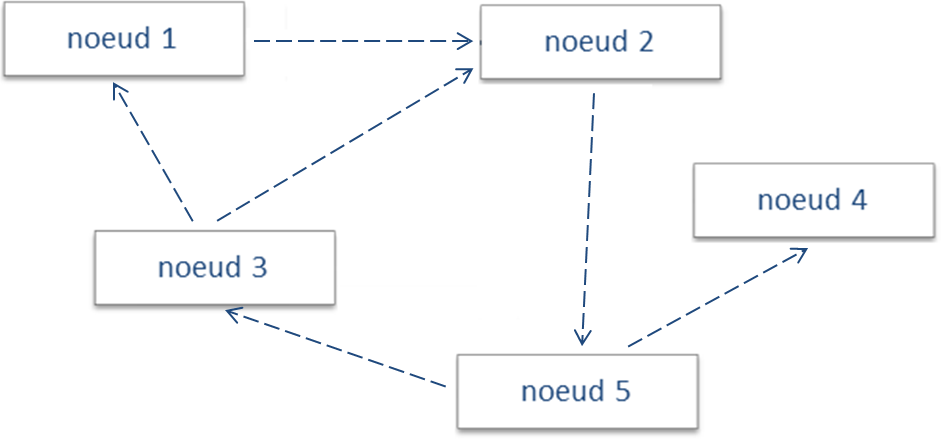
Dans le cas d’un réseau social par exemple, il peut être intéressant d’utiliser ce modèle, car il est plus facile retrouver une personne selon ses relations que selon son nom.
(Note : si Facebook n’utilise pas ce modèle c’est parce qu’il effectue beaucoup de logging, il est donc plus adapté à l’orienté colonne).
Les solutions du marché
Mongo DB
- écrit en C++
- garde des propriétés du SQL, à savoir l’indexation et les requetes
- orienté document
- mirroring maitre /esclave (copie automatique de la base possible, ce qui induit de la redondance mais augmente la sécurité)
- interprète les requêtes javascript (coté serveur)
- une table vide occupe environs 200Mo
- la taille maximale d’un objet est 4Mo. Pour pouvoir stocker les objets volumineux MongoDB implémente son propre système de découpage GridFS)
=> il est utilisé dans le cas où on recherche des performances élevées sur des bases de grande taille.
Cassandra
- initié par Facebook
- écrit en Java
- orienté colonne
- utilise un protocole de sérialisation créé par facebook et maintenant repris par Apache : Thrift
- optimisé pour l’écriture (d’où le développement d’un outil de sérialisation spécifique, pour le stockage de données ayant la même “base”) -> écrit plus rapidement qu’il ne lit
=> à utiliser dans le cas ou on doit surtout stocker (écrire) des données plus que les lire. Il peut aussi être utile si l’architecture complète doit être en Java.
Neo4j
- écrit en Java
- orienté Graph
- utilise le protocole HTTP/REST
- indexe les noeuds et les relations
- une interface web d’administration est intégrée
- scriptable en Groovy (langage alternatif au Java, qui s’exécute aussi dans une JVM)
- respecte entièrement le concept ACID (atomicity, consistency, isolation, durability) qui garantie que les transactions soient faites de manière sure.
=> à utiliser dans le cas de graphes riches et complexes (représentation de réseaux routiers ou de relations sociales)
Exemple d’utilisation avec MongoDB
Installation de MongoDB
http://www.youtube.com/watch?v=TQibIMMawLM
Insertion, affichage depuis la console MongoDB
Pour démarrer MongoDB:
/<MongoDB PATH>/bin/./mongod
Pour ouvrir la console de MongoDB:
/<MongoDB PATH>/bin/./mongo
Pour choisir la base de données:
use nom_de_la_base
Si la base n’existe pas, elle sera crée.
Exemple d’insertion d’un enregistrement:
var article = {
titre: 'Exemple MongoDB pour INTES',
texte: "Texte de l’article à ajouter",
date: '10-05-2012',
auteur: 'Jérémy et Joan'
}
db.articles.insert(article);
L’article sera ainsi ajouté dans la collection “articles” de la base de données en cours d’utilisation.
Pour afficher les enregistrements d’une collections, il suffit d’utiliser la commande suivante:
db.articles.find( );
Il est également possible d’indiquer des critères, comme par exemple le titre:
db.articles.find( { titre: 'Exemple MongoDB pour INTES' });
MongoDB et PHP
MongoDB doit être démarré, voir le chapitre précédent si besoin.
Il faut tout d’abord se connecter à la base de données:
$con = new Mongo(); // Pour se connecter à une base en localhost
Il faut ensuite sélectionné la base de données sur laquelle on va travailler:
$db = $con->nombasededonnees;
L’exemple du chapitre précédent devient:
$article = array(“titre” => 'Exemple MongoDB pour INTES', “texte” => ‘Texte de l’article à ajouter’, “date” => ‘2012-05-10’, “auteur” => ‘Jérémy et Joan’, “commentaires” => array(array(“texte” => 'Merci pour l’exemple', “date” => ‘2012-05-11’, “auteur” => 'Anonymous') ) ); $con->$db->articles->insert($article);
Vous trouvez l’archive contenant les pages php utilisées lors de la démonstration ici. Cet exemple permet d’ajouter un article dans une base de données, de leur ajouter des commentaires et d’afficher l’ensemble des enregistrements d’une collection. Pour tester l’exemple sur votre poste, il suffit d’extraire le contenu de l’archive à la racine de votre serveur apache.
Outils d’administration de la base de données
Il existe divers outils pour administrer les bases de données noSQL. Nous avons pour notre part utilisé PhpMoAdmin qui est spécifique à Mongo DB.
sources :
comparatif des NoSQL : http://kkovacs.eu/cassandra-vs-mongodb-vs-couchdb-vs-redis
explication NoSQL :