Le Cloud Computing: Comment installer son Cloud privé
[A.Deotto – A.Durand – FI13]
Le Cloud computing, littéralement l’informatique dans les nuages est un concept qui consiste à déporter sur des serveurs distants des stockages et des traitements informatiques traditionnellement localisés sur des serveurs locaux ou sur le poste de l’utilisateur.
Le Cloud Computing
1. Présentation
Plus précisément selon le National Institute of Standards and Technology (NIST), le cloud computing est l’accès via le réseau, à la demande et en libre-service à des ressources informatiques virtualisées et mutualisées.
Les utilisateurs ou les entreprises ne sont plus gérants de leurs serveurs informatiques mais peuvent ainsi accéder de manière évolutive à de nombreux services en ligne sans avoir à gérer l’infrastructure sous-jacente, souvent complexe. Les applications et les données ne se trouvent plus sur l’ordinateur local, mais « dans le cloud » composé d’un certain nombre de serveurs distants, interconnectés au moyen d’une excellente bande passante, indispensable à la fluidité du système. L’accès au service se fait par une application standard facilement disponible, la plupart du temps un navigateur web.
Le concept d’informatique dans le nuage est comparable à celui de la distribution de l’énergie électrique. La puissance de calcul et de stockage de l’information est proposée à la consommation par des entreprises spécialisées et facturé d’après l’utilisation réelle. De ce fait, les entreprises n’ont plus besoin de serveurs dédiés, mais confient le travail à effectuer à une entreprise qui leur garantit une puissance de calcul et de stockage à la demande.
Selon les approches des entreprises, se distinguent trois formes de Cloud computing :
- les clouds privés internes, gérés en interne par une entreprise pour ses besoins,
- les clouds privés externes, dédiés aux besoins propres d’une seule entreprise, mais dont la gestion est externalisée chez un prestataire,
- et les clouds publics, gérés par des entreprises spécialisées qui louent leurs services à de nombreuses entreprises.
Le National Institute of Standards and Technology en a donné une définition succincte qui reprend ces principes de base : « L’informatique dans les nuages est un modèle pratique, à la demande, pour établir un accès par le réseau à un réservoir partagé de ressources informatiques configurables (réseau, serveurs, stockage, applications et services) qui peuvent être rapidement mobilisées et mises à disposition en minimisant les efforts de gestion ou les contacts avec le fournisseur de service. »
2. Modèle du Cloud Computing
Le Cloud a émergé principalement pour répondre aux exigences de continuité et de qualité du service. Afin d’établir un service entre un client final et un fournisseur de services, il faut assurer la flexibilité et la disponibilité des 4 niveaux qui composent le Cloud :
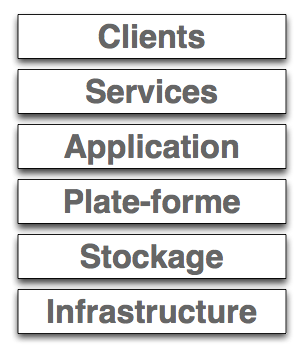
- l’application, qui est en contact avec le client ;
- la plate-forme, qui exécute l’application ;
- l’infrastructure, qui est le support de la plate-forme ;
- les données, qui sont fournies sur demande.
Les moyens employés sont essentiellement l’isolation verticale et le découpage horizontal de chaque niveau. Il faut en effet toujours être en mesure de remplacer chaque élément de la solution globale pour que le service au client final ne s’interrompe jamais. L’isolation est assurée par des normalisations existantes ou à inventer, et est obligatoire, car les 4 niveaux étant de nature différentes, ils ne peuvent s’interpénétrer.
Même si les techniques utilisées pour atteindre ce résultat ne sont pas fixées, elles comportent généralement au moins la virtualisation et la décomposition granulaire (décomposition d’entités en parties). En cela, il y a un rapprochement évident avec la philosophie générale d’Unix, qui décompose toute fonction finale en briques élémentaires simples, stables et compréhensibles.
Le Cloud computing est ainsi décomposé en 4 niveaux correspondant aux termes généralement notés ainsi :
- Software as a Service (SaaS) : l’application est découpée en brique élémentaires appelées services, qui peuvent être recomposées librement pour réaliser une fonction de plus haut niveau (ex : un service de cartographie style GoogleMap ajouté dans un site de vente de biens immobiliers.).
Le SaaS, souvent associé au Cloud computing, peut aussi être vu comme un modèle économique de consommation des applications. Consommées et payées à la demande (par utilisateur et par minute d’utilisation par exemple) et non plus acquises par l’achat de licences, le SaaS peut donc à ce titre reposer sur une infrastructure informatique dans le nuage.
- Platform as a Service (PaaS) : la plate-forme est granulaire : Elle est composée de briques utilisant des langages de programmation de haut niveau, généralement des langages de script (console de commande, Python, SQL, serveur d’application, etc.).
Flexibiliser ce niveau correspond à offrir un environnement d’exécution pour ces langages de haut niveau, tout en faisant disparaître la complexité inhérente à leur bon fonctionnement. Ce qui compte, c’est que la fonction logicielle soit assurée correctement et continuellement. On utilise pour cela des flottes (ou nuages) de serveurs. Les techniques utilisées sont variées : le basculement (fail-over), la répartition de charge (load-balancing)…
- Infrastructure as a Service (IaaS) : l’infrastructure est virtualisée afin que les ressources puissent être allouées et re-libérées à la demande, sans interruption. C’est à ce niveau qu’est crée la plateforme et que sont exécutés les langages de programmation de bas niveau (C++, C, assembleur, etc.). C’est le niveau du système d’exploitation et de l’accès aux fichiers.
- Data as a Service (DaaS) : les données sont fournies à un endroit précis. Ces données sont nettoyées, enrichies et à disposition de différents systèmes, applications ou utilisateurs, quel que soit l’endroit où ils sont dans leur organisation ou sur le réseau.

3. Le Cloud privé comme solution
Inconvénients du Cloud Computing public
Budget : Les besoins en bande passante peuvent faire exploser le budget. Par exemple, pour une grande entreprise et/ou ayant un besoin fort en ressources, il sera peut être préférable de trouver une autre solution.
Cadre légal : Il n’y a aucun accès physique aux données transférées dans le Cloud. Elles ne sont pas forcément présentes sur le territoire national. Il est ainsi difficile de connaitre précisément à quel endroit elles sont stockées. De plus, selon le type d’activité d’une entreprise, la loi peut imposer de pouvoir localiser précisément et rapidement les données, tout en ayant la possibilité d’avoir un accès physique sur celles-ci. Ceci est donc problématique pour un bon nombre d’entreprises.
Débit internet : Le Cloud utilisant de manière intensive le transfert de données, il est obligatoire d’avoir une connexion très performante. Ce qui est difficile, voire impossible pour des entreprises situées dans des endroits peu desservis.
L’optimisation des applications : Malgré une connexion internet rapide, avec un débit garanti, certaines applications web peuvent s’avérer être très lentes ou, en tout cas, limitées par rapport à des applications fonctionnant sur son propre ordinateur. La vitesse d’exécution peut prédominer dans certaines sociétés, et adopter le Cloud signifierait obligatoirement une perte de vitesse, matérialisée par le temps de transmission des données.
La pérennité du service : Toutes les entreprises utilisant le Cloud public sont dépendantes de leur hébergeur. L’arrêt de son activité, par exemple, pourrait être très problématique. En effet, un changement d’hébergeur prend du temps, et peut nécessiter un recodage des applications.
Confidentialité et sécurité des données : Les données sont hébergées en dehors de l’entreprise. Ceci peut donc poser un risque potentiel fort pour l’entreprise de voir ses données mal utilisées ou volées. C’est actuellement le problème majeur du Cloud Computing publique.
Le Cloud Computing Privé
Si le Cloud Computing public propose des ressources informatiques hébergées (serveurs, stockage, puissance de calcul, applications…) distantes et mutualisées, les offres de Cloud Computing privées se distinguent par leur aspect dédié. Leur usage est réservé pour une seule entreprise, ceci dans le but de répondre à un besoin personnalisé de ressources informatiques.
Une nuance dans l’appellation Cloud privé existe cependant. Ainsi, les entreprises qui décident de conserver la maîtrise de leurs infrastructures virtualisées (datacenters) et qui souhaitent fournir des ressources à la demande mettront en place un Cloud privé interne. Un type de Cloud à travers lequel les DSI sont propriétaires de leurs infrastructures, auxquelles elles accèdent par le biais d’un réseau sécurisé, interne et fermé.
Une notion qui n’est pas la même pour le Cloud privé externe qui est mis à disposition par de nombreux acteurs et notamment des hébergeurs (OVH, Colt, Prosodie…) ou des SSII spécialistes de l’infogérance et de l’externalisation (Atos Origin, Capgemini, Sogeti…) ou encore des constructeurs (HP, IBM, VMware…).
Tout comme le Cloud Computing public, le Cloud privé repose sur quatre briques technologiques complémentaires et indissociables. Il s’agit de la virtualisation, des serveurs, du stockage et du réseau. Un ensemble de briques « chapeauté » par une cinquième, à savoir une solution d’administration et d’allocation dynamique des ressources virtuelles sous forme de services.
Nous allons développer notre raisonnement sur une solution de Cloud privé interne. Celui-ci va permettre de conserver les avantages (où la plupart des avantages) du Cloud public, tout en retirant bon nombre d’inconvénients, surtout en ce qui concerne la sécurité des données (puisque celles-ci sont hébergées directement dans les locaux de l’entreprise).
Etude de cas : installation du Cloud privé ownCloud
1. Description et mise en place
Services du Cloud ownCloud
 ownCloud est sorti en version 3 le 30 janvier 2012. Ce projet, sous licence AGPL et débuté en 2010, se veut être une alternative libre aux solutions propriétaires de stockage en ligne. Nouveauté pour cette troisième version, une entreprise du même nom chapeaute maintenant le projet et va proposer des solutions payantes basées sur le projet libre.
ownCloud est sorti en version 3 le 30 janvier 2012. Ce projet, sous licence AGPL et débuté en 2010, se veut être une alternative libre aux solutions propriétaires de stockage en ligne. Nouveauté pour cette troisième version, une entreprise du même nom chapeaute maintenant le projet et va proposer des solutions payantes basées sur le projet libre.
En plus d’une interface web qui permet de visualiser, partager et éditer ses données, ownCloud implémente des protocoles standards comme WebDAV pour l’accès aux fichiers, CardDAV pour l’accès aux contacts et, CalDAV pour le calendrier, ce qui permet de le synchroniser avec les OS les plus courants.
Un serveur ownCloud est donc accessible depuis tous les OS (Linux, Win, Mac et autres), mais aussi via des applications mobiles. ownCloud offre aussi certaines possibilités, comme écouter la musique partagée en streaming ou gérer un calendrier et des contacts qui peuvent être synchronisés sur tous les clients supportant CardDAV/CalDAV ( Kontact, Evolution, Thunderbird…).
Pré-requis à l’installation
Pour un Cloud privé interne, le choix de l’infrastructure (matérielle et logicielle) va être fait en fonction du type de cloud (hébergement d’applications, espace de stockage…) et de son usage (personnel ou pluri-utilisateurs).
Au niveau matériel, le principal aspect à prendre en compte pour notre installation est la capacité de stockage. En effet, ce type de Cloud n’étant pas destiné à héberger des applications, la puissance de calcul du serveur n’est pas un critère de choix déterminant.
Au niveau logiciel, ownCloud nécessite un environnement Linux. Afin de mettre en place le serveur web, nous allons utiliser une architecture de type LAMP intégrant les composants Apache, MySQL et Php.

Installation
Etant donné que nous n’avions pas accès à un serveur web, nous en avons mis en place un, localement. Pour cela, nous avons virtualisé l’environnement Linux Ubuntu sur un environnement Windows grâce au logiciel de virtualisation VirtualBox.
Ensuite, nous avons installé les paquets nécessaires au déploiement d’un serveur local, à savoir l’ensemble des composants de LAMP. Un driver ODBC a également été nécessaire afin de permettre au Cloud de manipuler la base de données mise à disposition.
En effet, ownCloud communique avec une base de données indiquée au moment de la configuration initiale. On en créé donc une à l’aide de la console : on se connecte par le biais de MySQL au serveur local à l’adresse 127.0.0.1. On créé alors une base de données à laquelle on affecte le nom désiré (l’utilisateur par défaut étant root).

On affecte ensuite les droits au serveur web sur le dossier ownCloud grâce à la commande CHOWN, de façon récursive grâce à l’option –R afin que tous les sous dossiers soient concernés.
![]()
Enfin, afin d’autoriser des opérations de download/upload plus importantes que par défaut, on augmente le poids maximum accepté dans le fichier de configuration du serveur php.ini.

La dernière étape de l’installation consiste à configurer le couple identifiant/mot de passe permettant d’accéder aux données du Cloud et à spécifier la base de données qui lui est reliée.
L’installation est alors terminée et on est en mesure d’exploiter les fonctionnalités offertes par ce Cloud à savoir principalement partager des fichiers.
Application à Telecom Lille 1
L’usage d’ownCloud, tel qu’il est développé actuellement, n’est pas vraiment adapté à une utilisation scolaire et ne pourrait se substituer à une plate-forme telle que Whippet. En effet, la gestion des droits n’est pas assez développée pour mettre en place certains contrôles. En effet, tous les utilisateurs faisant partie d’un même groupe disposent des droits de lecture, de création, de modification, mais aussi de suppression. Dans le cadre de l’école, cela reviendrait à autoriser tous les étudiants qui ont accès aux ressources à supprimer n’importe quel contenu sans l’accord d’un modérateur.
D’autre part, le système d’exploration des fichiers n’étant pas personnalisable, il ne se révèle pas d’une grande ergonomie : par rapport à un site tel que whippet, la recherche des cours peut très vite devenir fastidieuse.
En revanche, si un tel Cloud continuait à être développé, il pourrait devenir intéressant pour l’école et serait, matériellement, installable sur l’infrastructure existante.
Vue d’ensemble des solutions de Cloud privé
Pour ceux qui souhaitent créer eux-mêmes leur infrastructure Cloud (Iaas) pour des raisons de sécurité, de coût ou de dépendance vis-à-vis d’un fournisseur, il existe désormais un certain nombre de solutions open source. Nous en avons sélectionné cinq :
open.eucalyptus.com
Issue d’un projet de recherche de l’université de Californie, cette plate-forme cloud open source est certainement la plus connue, car intégr
ée dans Ubuntu Server et Debian. Ecrite en C, Java et Python, elle permet de créer des clouds Iaas (Infrastructure as a service) de type privé ou hybride, supporte des machines virtuelles Linux ainsi que les hyperviseurs Xen et KVM. Par ailleurs, elle est compatible avec EC2 d’Amazon. Il existe également une version propriétaire commercialisée par la société Eucalyptus Systems. Il apporte des fonctionnalités supplémentaires comme le support de VMware, celui des machines virtuelles Windows et l’intégration SAN.

opennebula.org
Cette plateforme purement open source permet de déployer des clouds privés, hybrides et publics. Ecrite en C++, Ruby et Shell, elle supporte les hyperviseurs Xen, KVM et VMware. Le support de Virtualbox est prévu. Comme Eucalyptus, elle permet de s’interfacer avec le cloud d’Amazon, EC2. Le projet est publié sous licence Apache 2.0. Par ailleurs, OpenNebula est soutenu par le projet européen Reservoir, qui propose une architecture complète pour la gestion de datacenters et la création de services cloud.

openstack.org
Créé en juillet 2010 par la Nasa et l’hébergeur américain Rackspace, ce projet purement open source est l’un des plus récents. Pour l’instant, la plate-forme n’est disponible qu’en version Developer Preview. Les premières versions définitives sont prévues d’ici à quelques semaines. Le développement se concentre à ce jour sur deux modules : Compute, pour la création de machines virtuelles, et Object Storage, pour le stockage de données. Plus de 30 fournisseurs soutiennent ce projet, dont AMD, Intel, Dell et Citrix. Openstack devrait également être intégré dans les prochaines versions d’Ubuntu, à côté d’Eucalyptus.
niftyname.org 
Seul projet d’origine française, la plate-forme Niftyname a été créée par l’hébergeur Ielo. Elle est diffusée sous licence GPLv3. Articulée autour d’un système de gestion écrit en Python, elle supporte l’hyperviseur KVM et permet de créer des machines virtuelles Windows, Linux, BSD et Solaris. Elle sait également gérer les fonctionnalités de stockage et de réseaux associés à ces machines.
nimbusproject.org
Issu du monde de la recherche, Nimbus permet de déployer un cloud de type Iaas. Diffusée sous licence Apache 2.0, cette plate-forme supporte les hyperviseurs Xen et KVM, et peut s’interfacer avec le cloud d’Amazon, EC2. Elle est associée à autre projet, baptisé Cumulus, qui permet de déployer des services de stockage en cloud, compatible avec le service Amazon S3. Nimbus a été déployé, entre autres, par un réseau d’universités américaines qui proposent des clouds en libre accès pour des projets de recherche.